Graphics Core Next (microarquitectura)
Graphics Core Next (GCN)[1] es el nombre en clave de una serie de microarquitecturas y una arquitectura de conjunto de instrucciones que AMD desarrolló para sus GPU como sucesora de su microarquitectura TeraScale. El primer producto con GCN se lanzó el 9 de enero de 2012.[2]
| Graphics Core Next | ||
|---|---|---|
| Información | ||
| Tipo | Microarquitectura | |
| Desarrollador | AMD | |
| Fecha de lanzamiento | 9 de enero de 2012 (13 años) | |
| https://www.amd.com/en/technologies/gcn | ||
GCN es una microarquitectura SIMD de conjunto de instrucciones reducido que contrasta con la arquitectura SIMD de palabra de instrucción muy larga de TeraScale.[3] GCN requiere considerablemente más transistores que TeraScale, pero ofrece ventajas para el cálculo de GPU de propósito general (GPGPU) debido a un compilador más simple.
Los chips gráficos GCN se fabricaron con CMOS a 28 nm y con FinFET a 14 nm (por Samsung Electronics y GlobalFoundries) y 7 nm (por TSMC), disponibles en modelos seleccionados en AMD Radeon HD 7000, HD 8000, RX 200, RX 300, RX 400, RX 500 y Vega series de tarjetas gráficas, incluida la Radeon VII lanzada por separado. GCN también se utilizó en la parte gráfica de las unidades de procesamiento acelerado (APUs - Accelerated Processing Units), como las de PlayStation 4 y Xbox One.
Conjunto de instrucciones
editarEl conjunto de instrucciones GCN es propiedad de AMD y fue desarrollado específicamente para GPU. No tiene microoperación para la división.
La documentación está disponible para:
- Graphics Core Next 1 instruction set
- Graphics Core Next 2 instruction set
- Graphics Core Next 3 and 4 instruction sets[4]
- Graphics Core Next 5 instruction set
- "Vega" 7nm instruction set architecture (también conocido como Graphics Core Next 5.1).
Un compilador de back-end LLVM está disponible para el conjunto de instrucciones GCN.[5] Es utilizado por Mesa 3D.
GNU Compiler Collection 9 es compatible con GCN 3 y GCN 5 desde 2019[6] para programas independientes de un solo subproceso, y GCC 10 también se descarga a través de OpenMP y OpenACC.[7]
MIAOW es una implementación RTL de código abierto de la microarquitectura AMD Southern Islands GPGPU.
En noviembre de 2015, AMD anunció su Iniciativa Boltzmann, cuyo objetivo es permitir la migración de aplicaciones basadas en CUDA a un modelo de programación C++ común.[8]
En el evento Super Computing 15, AMD mostró un compilador de cómputo heterogéneo (HCC - Heterogeneous Compute Compiler), un controlador de Linux sin periféricos y una infraestructura de tiempo de ejecución HSA para computación de alto rendimiento de clase de clúster, y una herramienta de interfaz de computación heterogénea para portabilidad (HIP - Heterogeneous-compute Interface for Portability) para portar aplicaciones CUDA al modelo C++ común antes mencionado.
Microarquitecturas
editarA partir de julio de 2017, el conjunto de instrucciones Graphics Core Next ha tenido cinco iteraciones. Las diferencias entre las primeras cuatro generaciones son bastante mínimas, pero la arquitectura GCN de quinta generación presenta procesadores de flujo muy modificados para mejorar el rendimiento y admitir el procesamiento simultáneo de dos números de menor precisión en lugar de un solo número de mayor precisión.[9]
Procesamiento de comandos
editar
Graphics Command Processor
editarEl procesador de comandos de gráficos (GCP - Graphics Command Processor) es una unidad funcional de la microarquitectura GCN. Entre otras tareas, se encarga del manejo de shaders asíncronos.[10]
Asynchronous Compute Engine
editarEl motor de cómputo asíncrono (ACE - Asynchronous Compute Engine) es un bloque funcional distinto que sirve para fines informáticos, cuyo propósito es similar al del procesador de comandos de gráficos.
Planificadores
editarDesde la tercera iteración de GCN, el hardware contiene dos planificadores: uno para programar "wavefronts" durante la ejecución del sombreador (Cu Scheduler o Compute Unit Scheduler) y el otro para programar la ejecución de dibujar y calcular colas. Este último ayuda al rendimiento mediante la ejecución de operaciones de cómputo cuando las unidades de cómputo (CUs - Compute Units) están infrautilizadas debido a los comandos de gráficos limitados por la velocidad o el ancho de banda de la canalización de funciones fijas. Esta funcionalidad se conoce como Async Compute.
Para un sombreador determinado, los controladores de la GPU también pueden programar instrucciones en la CPU para minimizar la latencia.
Procesador geométrico
editar
El procesador de geometría contiene un Ensamblador de geometría, un Teselador y un Ensamblador de vértices.
El Teselador es capaz de hacer teselado en hardware según lo definido por Direct3D 11 y OpenGL 4.5 (consulte AMD el 21 de enero de 2017),[11] y sucedió a ATI TruForm y al teselado de hardware en TeraScale como el núcleo de propiedad intelectual de semiconductores más reciente de AMD.
Unidades de cómputo
editarUna unidad de cómputo (CU - compute unit) combina 64 procesadores de sombreado con 4 unidades de mapeo de textura (TMUs - texture mapping units).[12][13] Las unidades de cómputo están separadas de las unidades de salida de procesamiento (ROP), pero se alimentan de ellas.[13] Cada unidad de cálculo consta de lo siguiente:
- Un planificador de CU
- Una sucursal y unidad de mensajes
- 4 unidades vectoriales SIMD de 16 carriles de ancho (SIMD-VU)
- 4 archivos de registro de uso general vectorial (VGPR) de 64 KiB
- 1 unidad escalar (SU - Scalar Unit)
- Un archivo GPR de 4 KiB
- Un recurso compartido de datos locales de 64 KiB
- 4 unidades de filtro de textura
- 16 unidades de carga/almacenamiento de textura
- Una caché de nivel 1 (L1) de 16 KiB
Cuatro unidades informáticas están conectadas para compartir un caché de instrucciones L1 de 16 KiB y un caché de datos L1 de 32 KiB, ambos de solo lectura. Una SIMD-VU opera con 16 elementos a la vez (por ciclo), mientras que una SU puede operar con uno a la vez (uno/ciclo). Además, la SU maneja algunas otras operaciones, como la ramificación.[14]
Cada SIMD-VU tiene una memoria privada donde almacena sus registros. Hay dos tipos de registros: registros escalares (S0, S1, etc.), que contienen un número de 4 bytes cada uno, y registros vectoriales (V0, V1, etc.), cada uno de los cuales representa un conjunto de 64 números de 4 bytes. En los registros vectoriales, cada operación se realiza en paralelo en los 64 números. que corresponden a 64 entradas. Por ejemplo, puede funcionar en 64 píxeles diferentes a la vez (para cada uno de ellos, las entradas son ligeramente diferentes y, por lo tanto, obtienes un color ligeramente diferente al final).
Cada SIMD-VU tiene espacio para 512 registros escalares y 256 registros vectoriales.
Planificador de CU
editarEl planificador CU es el bloque funcional del hardware, que elige qué frentes de onda ejecuta la SIMD-VU. Selecciona una SIMD-VU por ciclo para la programación. Esto no debe confundirse con otros programadores de hardware o software.
Wavefront
editarUn shader es un pequeño programa escrito en GLSL que realiza el procesamiento de gráficos, y un kernel es un pequeño programa escrito en OpenCL que realiza el procesamiento GPGPU. Estos procesos no necesitan tantos registros, pero sí necesitan cargar datos del sistema o de la memoria gráfica. Esta operación viene con una latencia significativa. AMD y Nvidia eligieron enfoques similares para ocultar esta latencia inevitable: la agrupación de múltiples hilos. AMD llama a ese grupo un "wavefront", mientras que Nvidia lo llama un "warp". Un grupo de subprocesos es la unidad más básica de programación de GPU que implementan este enfoque para ocultar la latencia. Es el tamaño mínimo de los datos procesados en modo SIMD, la unidad de código ejecutable más pequeña y la forma de procesar una sola instrucción en todos los subprocesos al mismo tiempo.
En todas las GPU GCN, un "wavefront" consta de 64 subprocesos, y en todas las GPU Nvidia, un "warp" consta de 32 subprocesos.
La solución de AMD es atribuir múltiples frentes de onda a cada SIMD-VU. El hardware distribuye los registros a los diferentes frentes de onda, y cuando un frente de onda está esperando algún resultado, que se encuentra en la memoria, el CU Scheduler asigna a la SIMD-VU otro frente de onda. Los frentes de onda se atribuyen por SIMD-VU. Las SIMD-VU no intercambian frentes de onda. Se puede atribuir un máximo de 10 frentes de onda por SIMD-VU (por lo tanto, 40 por CU).
AMD CodeXL muestra tablas con la relación entre el número de SGPR y VGPR con el número de frentes de onda, pero esencialmente, para SGPRS es entre 104 y 512 por número de frentes de onda, y para VGPRS es 256 por número de frentes de onda.
Tenga en cuenta que, junto con las instrucciones SSE, este concepto del nivel más básico de paralelismo a menudo se denomina "ancho de vector". El ancho del vector se caracteriza por el número total de bits que contiene.
Unidad vectorial SIMD
editarCada Unidad Vectorial SIMD tiene:
- Una unidad aritmética lógica (ALU - Arithmetic Logic Unit) de vector de punto flotante y entero de 16 carriles
- Archivo de registro de uso general vectorial (VGPR) de 64 KiB
- Un contador de programa de 48 bits
- Búfer de instrucciones para 10 frentes de onda (cada frente de onda es un grupo de 64 subprocesos, o el tamaño de un VGPR lógico)
- Un frente de onda de 64 hilos emite a una unidad SIMD de 16 carriles durante cuatro ciclos
Cada SIMD-VU tiene 10 búferes de instrucciones de frente de onda y se necesitan 4 ciclos para ejecutar un frente de onda.
Bloques de aceleración de audio y video
editarMuchas implementaciones de GCN suelen ir acompañadas de varios de los otros bloques ASIC de AMD. Incluyendo, entre otros, el decodificador de video unificado, el motor de codificación de video y AMD TrueAudio.
Motor de codificación de video
editarEl motor de codificación de video es un ASIC de codificación de video, introducido por primera vez con la serie Radeon HD 7000.[15]
La versión inicial de VCE agregó soporte para codificar cuadros I y P H.264 en el formato de píxel YUV420, junto con codificación temporal SVE y modo de codificación de pantalla, mientras que la segunda versión agregó soporte de cuadro B para cuadros I YUV420 y YUV444.
VCE 3.0 formó parte de la tercera generación de GCN, agregando escalado de video de alta calidad y el códec HEVC (H.265).
VCE 4.0 era parte de la arquitectura Vega y posteriormente fue reemplazado por Video Core Next.
Memoria virtual unificada
editarEn una vista previa en 2011, AnandTech escribió sobre la memoria virtual unificada, compatible con Graphics Core Next.[16]
|




Heterogeneous System Architecture (HSA)
editar
Algunas de las características específicas de HSA implementadas en el hardware necesitan soporte del kernel del sistema operativo (sus subsistemas) y/o de controladores de dispositivos específicos. Por ejemplo, en julio de 2014, AMD publicó un conjunto de 83 parches que se fusionarían con la línea principal 3.17 del kernel de Linux para admitir sus tarjetas gráficas Radeon basadas en Graphics Core Next. El llamado controlador de kernel HSA reside en el directorio/drivers/gpu/hsa, mientras que los controladores de dispositivos gráficos DRM residen en/drivers/gpu/drm[19] y aumente los controladores DRM ya existentes para las tarjetas Radeon.[20] Esta primera implementación se centra en una sola APU "Kaveri" y funciona junto con el controlador de gráficos del kernel Radeon (kgd) existente.
Planificadores de hardware
editarLos planificadores de hardware se utilizan para realizar la programación[21] y descargar la asignación de colas de cómputo a las ACE desde el controlador al hardware, almacenando en búfer estas colas hasta que haya al menos una cola vacía en al menos una ACE. Esto hace que el HWS asigne inmediatamente colas almacenadas en búfer a las ACE hasta que todas las colas estén llenas o no haya más colas para asignar de manera segura.[22]
Parte del trabajo de programación realizado incluye colas priorizadas que permiten que las tareas críticas se ejecuten con una prioridad más alta que otras tareas sin requerir que las tareas de menor prioridad se adelanten para ejecutar la tarea de alta prioridad, lo que permite que las tareas se ejecuten simultáneamente con las tareas de alta prioridad. programado para acaparar la GPU tanto como sea posible mientras permite que otras tareas usen los recursos que las tareas de alta prioridad no están usando.[21] Estos son esencialmente motores de cómputo asíncronos que carecen de controladores de despacho.[21] Se introdujeron por primera vez en la microarquitectura GCN de cuarta generación,[21] pero estaban presentes en la microarquitectura GCN de tercera generación con fines de prueba interna.[23] Una actualización del controlador ha habilitado los programadores de hardware en piezas GCN de tercera generación para uso en producción.[21]
Primitive Discard Accelerator
editarEsta unidad descarta los triángulos degenerados antes de que entren en el sombreador de vértices y los triángulos que no cubren ningún fragmento antes de que entren en el sombreador de fragmentos.[24] Esta unidad se introdujo con la microarquitectura GCN de cuarta generación.[24]
Generaciones
editarGraphics Core Next 1
editarLa microarquitectura GCN 1 se utilizó en varias tarjetas gráficas de la serie Radeon HD 7000.
.jpg)
- Compatibilidad con direccionamiento de 64 bits (espacio de direcciones x86-64) con espacio de direcciones unificado para CPU y GPU[16]
- Soporte para PCI-E 3.0[25]
- La GPU envía solicitudes de interrupción a la CPU en varios eventos (como fallas de página)
- Soporte para texturas parcialmente residentes,[26] que permiten el soporte de memoria virtual a través de extensiones DirectX y OpenGL
- Compatibilidad con AMD PowerTune, que ajusta dinámicamente el rendimiento para mantenerse dentro de un TDP específico[27]
- Soporte para Manto (API)
Hay motores de cómputo asíncronos que controlan el cómputo y el despacho.[14][28]
ZeroCore Power
editarZeroCore Power es una tecnología de ahorro de energía inactiva prolongada que apaga las unidades funcionales de la GPU cuando no se usan.[29] La tecnología AMD ZeroCore Power complementa AMD PowerTune.
Chips
editarGPU discretas (familia de Southern Islands):
- Hainan
- Oland
- Cape Verde
- Pitcairn
- Tahiti
Graphics Core Next 2
editar

La segunda generación de GCN se introdujo con Radeon HD 7790 y también se encuentra en Radeon HD 8770, R7 260/260X, R9 290/290X, R9 295X2, R7 360 y R9 390/390X, así como en Steamroller. APU de escritorio "Kaveri" y APU móviles "Kaveri" y en las APU "Beema" y "Mullins" basadas en Puma. Tiene múltiples ventajas sobre el GCN original, incluida la compatibilidad con FreeSync, AMD TrueAudio y una versión revisada de la tecnología AMD PowerTune.
La segunda generación de GCN introdujo una entidad llamada "Shader Engine" (SE). Un Shader Engine consta de un procesador de geometría, hasta 44 CU (chip Hawaii), rasterizadores, ROP y caché L1. No forma parte de un Shader Engine el procesador de comandos de gráficos, los 8 ACE, los controladores de memoria y caché L2, así como los aceleradores de audio y video, los controladores de pantalla, los 2 controladores DMA y la interfaz PCIe.
El A10-7850K "Kaveri" contiene 8 CU (unidades de cómputo) y 8 motores de cómputo asíncronos para la programación independiente y el envío de elementos de trabajo.[30]
En AMD Developer Summit (APU) en noviembre de 2013, Michael Mantor presentó la Radeon R9 290X.[31]
Chips
editarGPU discretas (familia Sea Islands):
- Bonaire
- Hawaii
integrado en las APU:
- Temash
- Kabini
- Liverpool (es decir, la APU que se encuentra en la PlayStation 4)
- Durango (es decir, la APU que se encuentra en Xbox One y Xbox One S)
- Kaveri
- Godavari
- Mullins
- Beema
- Carrizo-L
Graphics Core Next 3
editar
La tercera generación de GCN[32] se introdujo en 2014 con Radeon R9 285 y R9 M295X, que tienen la GPU "Tonga". Cuenta con un rendimiento de teselación mejorado, compresión de color delta sin pérdidas para reducir el uso de ancho de banda de memoria, un conjunto de instrucciones actualizado y más eficiente, un nuevo escalador de alta calidad para video y un nuevo motor multimedia (codificador/descodificador de video). La compresión de color Delta es compatible con Mesa.[33] Sin embargo, su rendimiento de doble precisión es peor en comparación con la generación anterior.[34]
Chips
editarGPU discretas:
- Tonga (familia Volcanic Islands), viene con UVD 5.0 (Unified Video Decoder)
- Fiji (familia (Pirate Islands), viene con UVD 6.0 y memoria de alto ancho de banda (HBM 1)
Integrado en las APU:
Graphics Core Next 4
editar

Las GPU de la familia Arctic Islands se introdujeron en el segundo trimestre de 2016 con la serie AMD Radeon RX 400. El motor 3D (es decir, GCA (matriz de gráficos y cómputo) o GFX) es idéntica a la que se encuentra en los chips Tonga.[36] Pero Polaris presenta un motor de controlador de pantalla más nuevo, UVD versión 6.3, etc.
Todos los chips basados en Polaris que no sean Polaris 30 se producen en el proceso FinFET de 14 nm, desarrollado por Samsung Electronics y con licencia para GlobalFoundries.[37] El Polaris 30 actualizado, un poco más nuevo, se basa en el nodo de proceso LP FinFET de 12 nm, desarrollado por Samsung y GlobalFoundries. La arquitectura del conjunto de instrucciones GCN de cuarta generación es compatible con la tercera generación. Es una optimización para 14 nm Proceso FinFET que permite velocidades de reloj de GPU más altas que con la tercera generación de GCN.[38] Las mejoras arquitectónicas incluyen nuevos programadores de hardware, un nuevo acelerador de descarte primitivo, un nuevo controlador de pantalla y un UVD actualizado que puede decodificar HEVC a resoluciones 4K a 60 cuadros por segundo con 10 bits por canal de color.
Chips
editarGPU discretas:[39]
- Polaris 10 (también con nombre en código Ellesmere) que se encuentra en las tarjetas gráficas de marca "Radeon RX 470" y "Radeon RX 480"
- Polaris 11 (también con nombre en código Baffin) que se encuentra en las tarjetas gráficas de la marca "Radeon RX 460" (también Radeon RX 560 D)
- Polaris 12 (también con nombre en código Lexa) que se encuentra en las tarjetas gráficas de marca "Radeon RX 550" y "Radeon RX 540"
- Polaris 20, que es un Polaris 10 actualizado (proceso LPP Samsung/GloFo FinFET de 14 nm) con relojes más altos, utilizado para tarjetas gráficas de marca "Radeon RX 570" y "Radeon RX 580"[40]
- Polaris 21, que es un renovado (LPP Samsung/GloFo FinFET de 14 nm) Polaris 11, utilizado para tarjetas gráficas de la marca "Radeon RX 560"
- Polaris 22, que se encuentra en las tarjetas gráficas de marca "Radeon RX Vega M GH" y "Radeon RX Vega M GL" (como parte de Kaby Lake-G)
- Polaris 23, que es un renovado ( LPP Samsung/GloFo FinFET de 14 nm) Polaris 12, utilizado para tarjetas gráficas de marca "Radeon Pro WX 3200" y "Radeon RX 540X" (también Radeon RX 640)[41]
- Polaris 30, que es un Polaris 20 actualizado (proceso LP GloFo FinFET de 12 nm) con relojes más altos, utilizado para tarjetas gráficas de la marca "Radeon RX 590"[42]
Además de las GPU dedicadas, Polaris se utiliza en las APU de PlayStation 4 Pro y Xbox One X, denominadas "Neo" y "Scorpio", respectivamente.
Rendimiento de precisión
editarEl rendimiento de FP64 de todas las GPU GCN de 4.ª generación es 1/16 del rendimiento de FP32.
Graphics Core Next 5
editar
AMD comenzó a publicar detalles de su próxima generación de arquitectura GCN, denominada "Unidad de cómputo de próxima generación", en enero de 2017.[38][43][44] Se esperaba que el nuevo diseño aumentara las instrucciones por reloj, velocidades de reloj más altas, soporte para HBM2, un espacio de direcciones de memoria más grande. Los conjuntos de chips de gráficos discretos también incluyen "HBCC (controlador de caché de alto ancho de banda)", pero no cuando están integrados en las APU.[45] Además, se esperaba que los nuevos chips incluyeran mejoras en las unidades de salida de Rasterización y Render. Los procesadores de flujo están muy modificados con respecto a las generaciones anteriores para admitir la tecnología Rapid Pack Math de matemáticas empaquetadas para números de 8 bits, 16 bits y 32 bits. Con esto, existe una ventaja de rendimiento significativa cuando se acepta una menor precisión (por ejemplo: procesar dos números de precisión media a la misma velocidad que un solo número de precisión).
Nvidia introdujo la rasterización y el binning basados en mosaicos con Maxwell,[46] y esta fue una razón importante para el aumento de la eficiencia de Maxwell. En enero, AnandTech asumió que Vega finalmente se pondría al día con Nvidia con respecto a las optimizaciones de eficiencia energética debido al nuevo "DSBR (Draw Stream Binning Rasterizer)" que se presentará con Vega.[47]
También agregó soporte para una nueva etapa de sombreado: sombreadores primitivos.[48][49] Los sombreadores primitivos proporcionan un procesamiento de geometría más flexible y reemplazan los sombreadores de vértices y geometría en una canalización de representación. A partir de diciembre de 2018, los sombreadores primitivos no se pueden usar porque aún no se han realizado los cambios requeridos en la API.[50]
Vega 10 y Vega 12 usan el proceso FinFET de 14 nm, desarrollado por Samsung Electronics y licenciado a GlobalFoundries. Vega 20 utiliza el Proceso FinFET de 7 nm desarrollado por TSMC.
Chips
editarGPU discretas:
- Vega 10 (proceso Samsung/GloFo FinFET de 14 nm) (también con nombre en código Greenland[51]) que se encuentra en "Radeon RX Vega 64", "Radeon RX Vega 56", "Radeon Vega Frontier Edition", "Radeon Pro V340", Radeon Pro WX 9100 y Tarjetas gráficas Radeon Pro WX 8200[52]
- Vega 12 (proceso Samsung/GloFo FinFET de 14 nm) que se encuentran en las tarjetas gráficas móviles de las marcas "Radeon Pro Vega 20" y "Radeon Pro Vega 16" [53]
- Vega 20 (proceso TSMC FinFET de 7 nm) que se encuentran en las tarjetas aceleradoras de marca "Radeon Instinct MI50" y "Radeon Instinct MI60",[54] tarjetas gráficas de marca "Radeon Pro Vega II" y "Radeon VII".[55]
Integrado en las APU:
- Raven Ridge[56] vino con VCN 1 que reemplaza a VCE y UVD y permite la decodificación VP9 de función fija completa.
Rendimiento de precisión
editarEl rendimiento de punto flotante de doble precisión (FP64) de todas las GPU GCN de 5.ª generación, excepto Vega 20, es 1/16 del rendimiento de FP32. Para Vega 20 con Radeon Instinct, esto es 1/2 del rendimiento de FP32. Para Vega 20 con Radeon VII esto es 1/4 del rendimiento de FP32.[57] Todas las GPU de 5.ª generación de GCN admiten cálculos de punto flotante de precisión media (FP16), que es el doble del rendimiento de FP32.
Comparación de chips GCN
editar- La tabla contiene solo chips de GPU discretos (incluido el móvil). Los chips APU (IGP) y de consola no se enumeran.
| ISA | Graphics Core Next[58] | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Microarquitectura | GCN 1 | GCN 2 | GCN 3 | GCN 4 | GCN 5 | |||||||||||
| Chip | Tahiti[59] | Pitcairn[60] | Cape Verde[61] | Oland[62] | Hainan[63] | Bonaire[64] | Hawaii[65] | Topaz[66] | Tonga[67] | Fiji[68] | Ellesmere[69] | Baffin[70] | Lexa[71] | Vega 10[72] | Vega 12[73] | Vega 20[74] |
| Nombre en clave1 | ? | ? | ? | Tiran | ? | ? | Ibiza | Iceland | ? | ? | Polaris 10 | Polaris 11 | Polaris 12 | Greenland | Treasure Refresh | Moonshot |
| Variantes del chip | New Zealand Malta |
Wimbledon
Curacao Neptune Trinidad |
Chelsea
Heathrow Venus Tropo |
Mars
Opal Litho |
Sun
Jet Exo Banks |
Saturn
Tobago Strato Emerald |
Vesuvius
Grenada |
Meso
Weston Polaris 24 |
Amethyst
Antigua |
Capsaicin | Polaris 20
Polaris 30 |
Polaris 21 | Polaris 23 | |||
| Fabricación | TSMC 28 nm | GlobalFoundries 14 nm / 12 nm (Polaris 30) | TSMC 7 nm | |||||||||||||
| Tamaño del chip (mm2) | 352 / 365 (Malta) | 212 | 123 | 77 | 56 | 160 | 438 | 125 | 366 | 596 | 232 | 123 | 103 | 495 | 331 | |
| Transistores (millones) | 4,313 | 2,800 | 1,500 | 950 | 690 | 2,080 | 6,200 | 1,550 | 5,000 | 8,900 | 5,700 | 3,000 | 2,200 | 12,500 | 13,230 | |
| Densidad de transistores (MTr/mm2) | 12.3 / 12.8 (Malta) | 13.2 | 12.2 | 12.3 | 13.0 | 14.2 | 12.4 | 13.7 | 14.9 | 24.6 | 24.4 | 21.4 | 25.3 | 40.0 | ||
| Planificadores de Hardware | 2 | 2 | ||||||||||||||
| Motores de cómputo asincrónicos | 2 | 8 | 8 | 4 | 4 | |||||||||||
| Motores de geometría | 2 | 1 | 2 | 4 | 4 | |||||||||||
| Motores de sombreador | 4 | 4 | 2 | |||||||||||||
| Unidades de cómputo | 32 | 20 | 10 / 8 (Chelsea) | 6 | 5 / 6 (Jet) | 14 | 44 | 6 | 32 | 64 | 36 | 16 | 10 | 64 | 20 | 64 |
| Stream processors | 2048 | 1280 | 640 / 512 (Chelsea) | 384 | 320 / 384 (Jet) | 896 | 2816 | 384 | 2048 | 4096 | 2034 | 1024 | 640 | 4096 | 1280 | 4096 |
| Unidad de mapeo de texturas | 128 | 80 | 40 / 32 (Chelsea) | 24 | 20 / 24 (Jet) | 56 | 176 | 24 | 128 | 256 | 144 | 64 | 40 | 256 | 80 | 256 |
| Unidad de salida de renderizado | 32 | 16 | 8 | 16 | 64 | 8 | 32 | 64 | 32 | 16 | 64 | 32 | 64 | |||
| Z/Stencil OPS | 128 | 64 | 16 | 64 | 256 | 16 | 128 | 256 | ||||||||
| Caché L1 (KB) | 16 por unidad de cómputo (CU) | |||||||||||||||
| Caché L2 (KB) | 768 | 512 | 256 | 128 / 256 (Jet) | 256 | 1024 | 256 | 768 | 2048 | 1024 | 512 | 4096 | 1024 | 4096 | ||
| Display core engine | 6.0 | 6.4 | 8.2 | 8.5 | 10.0 | 11.2 | 12.0 | 12.1 | ||||||||
| Decodificador de video unificado | 3.2 | 4.0 | 4.2 | 5.0 | 6.0 | 6.3 | 7.0 | 7.2 | ||||||||
| Motor de codificación de video | 1.0 | 2.0 | 3.0 | 3.4 | 4.0 | 4.1 | ||||||||||
| Lanzamiento2 | Diciembre 2011 | Marzo 2012 | Febrero 2012 | Enero 2013 | Mayo 2015 | Marzo 2013 | Octubre 2013 | 2014 | Agosto 2014 | Junio 2015 | Junio 2016 | Agosto 2016 | Abril 2017 | Junio 2017 | Noviembre 2018 | Noviembre 2018 |
| Notas | mobile/OEM | mobile/OEM | mobile | |||||||||||||
1 Los nombres de código antiguos como Treasure (Lexa) o Hawaii Refresh (Ellesmere) no se incluyen en la lista.
2 Fecha de lanzamiento inicial. No se enumeran las fechas de lanzamiento de variantes de chips como Polaris 20 (abril de 2017).
Véase también
editarReferencias
editar- ↑ AMD Developer Central (31 de enero de 2014). «GS-4106 The AMD GCN Architecture – A Crash Course, by Layla Mah». Slideshare.net.
- ↑ «AMD Launches World’s Fastest Single-GPU Graphics Card – the AMD Radeon™ HD 7970». amd.com. 20 de enero de 2015. Archivado desde el original el 20 de enero de 2015. Consultado el 23 de febrero de 2023.
- ↑ Gulati, Abheek (11 de noviembre de 2019). «An Architectural Deep-Dive into AMD's TeraScale, GCN & RDNA GPU Architectures». Medium (en inglés). Consultado el 12 de diciembre de 2021.
- ↑ «AMD community forums». Community.amd.com.
- ↑ «LLVM back-end amdgpu». Llvm.org.
- ↑ «GCC 9 Release Series Changes, New Features, and Fixes». Consultado el 13 de noviembre de 2019.
- ↑ «AMD GCN Offloading Support». Consultado el 13 de noviembre de 2019.
- ↑ «AMD Boltzmann Initiative – Heterogeneous-compute Interface for Portability (HIP)». 16 de noviembre de 2015. Archivado desde el original el 26 de enero de 2016. Consultado el 8 de diciembre de 2019.
- ↑ Smith, Ryan (5 de enero de 2017). «The AMD Vega GPU Architecture Preview». Anandtech.com. Consultado el 11 de julio de 2017.
- ↑ Smith, Ryan. «AMD Dives Deep On Asynchronous Shading». Anandtech.com.
- ↑ «Conformant Products». Khronos.org. 26 de octubre de 2017.
- ↑ Compute Cores Whitepaper. AMD. 2014. p. 5.
- ↑ a b Smith, Ryan (21 de diciembre de 2011). «AMD's Graphics Core Next Preview». Anandtech.com. Consultado el 18 de abril de 2017.
- ↑ a b Mantor, Michael (15 de junio de 2011). «AMD Graphics Core Next». AMD. Consultado el 15 de julio de 2014. «Asynchronous Compute Engine (ACE)».
- ↑ «White Paper AMD UnifiedVideoDecoder (UVD)». 15 de junio de 2012. Consultado el 20 de mayo de 2017.
- ↑ a b «Not Just A New Architecture, But New Features Too». AnandTech. 21 de diciembre de 2011. Consultado el 11 de julio de 2014.
- ↑ /technical-look-amds-kaveri-architecture/ «Microarquitectura Kaveri». SemiPreciso. 15 de enero de 2014.
- ↑ Airlie, Dave (26 de noviembre de 2014). «Merge AMDKFD». freedesktop.org. Consultado el 21 de enero de 2015.
- ↑ «/drivers/gpu/drm». Kernel.org.
- ↑ «[PATCH 00/83] AMD HSA kernel driver». LKML. 10 de julio de 2014. Consultado el 11 de julio de 2014.
- ↑ a b c d e Angelini, Chris (29 de junio de 2016). «AMD Radeon RX 480 8GB Review». Tom's Hardware. p. 1. Consultado el 11 de agosto de 2016.
- ↑ «Dissecting the Polaris Architecture». 2016. Archivado desde el original el 20 de septiembre de 2016. Consultado el 12 de agosto de 2016.
- ↑ Shrout, Ryan (29 de junio de 2016). «The AMD Radeon RX 480 Review – The Polaris Promise». PC Perspective. p. 2. Archivado desde el original el 10 de octubre de 2016. Consultado el 12 de agosto de 2016.
- ↑ a b Smith, Ryan (29 de junio de 2016). «The AMD Radeon RX 480 Preview: Polaris Makes Its Mainstream Mark». AnandTech. p. 3. Consultado el 11 de agosto de 2016.
- ↑ «AMD Radeon HD 7000 Series to be PCI-Express 3.0 Compliant». TechPowerUp. Consultado el 21 de julio de 2011.
- ↑ «AMD Details Next Gen. GPU Architecture». Consultado el 3 de agosto de 2011.
- ↑ Tony Chen, Jason Greaves, «AMD's Graphics Core Next (GCN) Architecture», AMD, archivado desde el original el 18 de enero de 2023, consultado el 13 de agosto de 2016.
- ↑ «AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute». AnandTech. 21 de diciembre de 2011. Consultado el 15 de julio de 2014. «AMD's new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing.»
- ↑ «Managing Idle Power: Introducing ZeroCore Power». AnandTech.com. 22 de diciembre de 2011. Consultado el 29 de abril de 2015.
- ↑ «AMD's Kaveri A10-7850K tested». AnandTech. 14 de enero de 2014. Consultado el 7 de julio de 2014.
- ↑ «AMD Radeon R9-290X». 21 de noviembre de 2013.
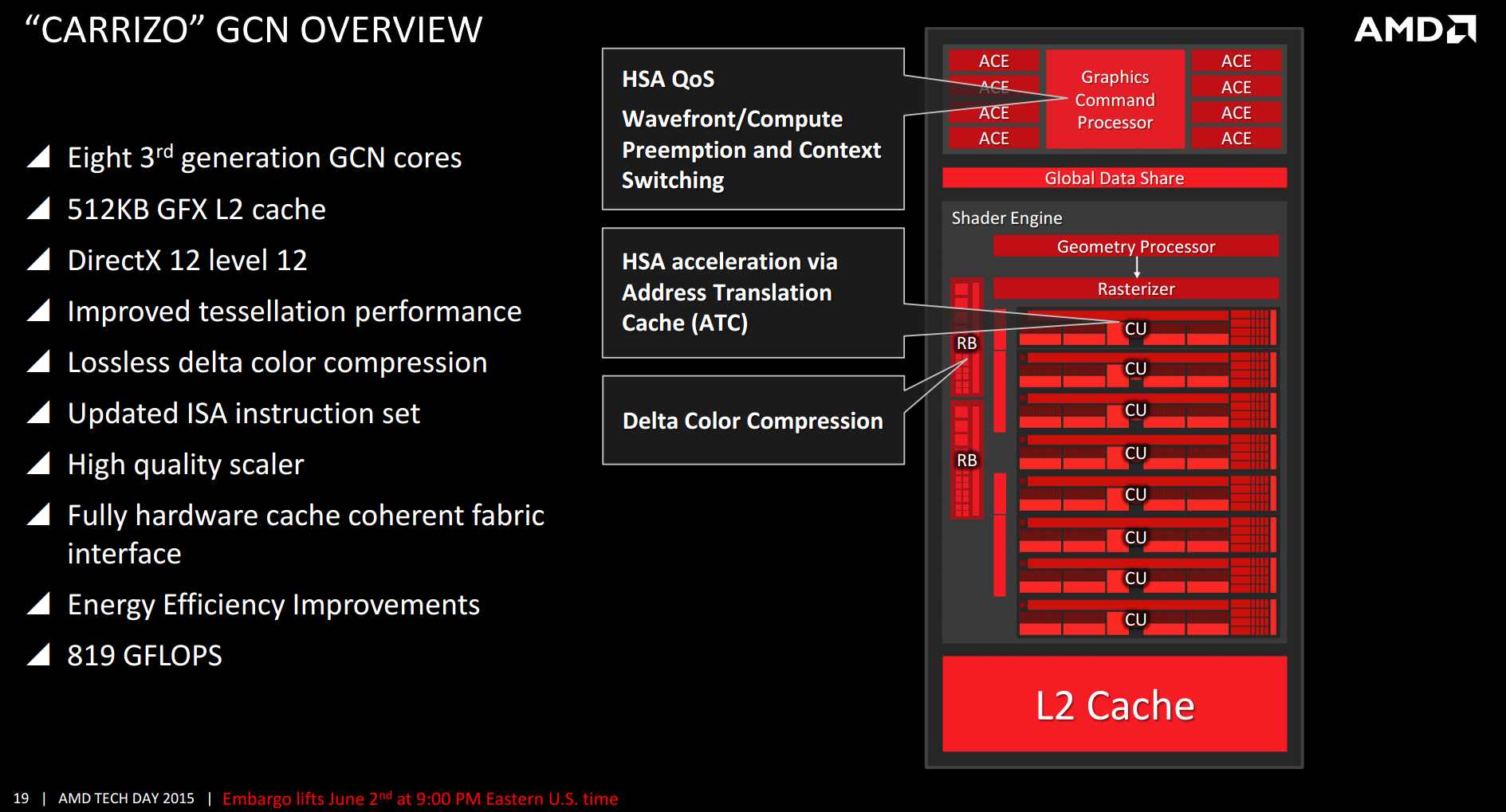
- ↑ «Carrizo Overview» (PNG). Images.anandtech.com. Consultado el 20 de julio de 2018.
- ↑ «Add DCC Support». Freedesktop.org. 11 de octubre de 2015.
- ↑ Smith, Ryan (10 de septiembre de 2014). «AMD Radeon R9 285 Review». Anandtech.com. Consultado el 13 de marzo de 2017.
- ↑ a b Cutress, Ian (1 de junio de 2016). «AMD Announces 7th Generation APU». Anandtech.com. Consultado el 1 de junio de 2016.
- ↑ «RadeonFeature». www.x.org.
- ↑ «Radeon Technologies Group – January 2016 – AMD Polaris Architecture». Guru3d.com.
- ↑ a b Smith, Ryan (5 de enero de 2017). «The AMD Vega Architecture Teaser: Higher IPC, Tiling, & More, coming in H1'2017». Anandtech.com. Consultado el 10 de enero de 2017.
- ↑ WhyCry (24 de marzo de 2016). «AMD confirms Polaris 10 is Ellesmere and Polaris 11 is Baffin». VideoCardz. Consultado el 8 de abril de 2016.
- ↑ «Fast vollständige Hardware-Daten zu AMDs Radeon RX 500 Serie geleakt». www.3dcenter.org.
- ↑ «AMD Polaris 23». TechPowerUp. Consultado el 12 de mayo de 2022.
- ↑ Oh, Nate (15 de noviembre de 2018). «The AMD Radeon RX 590 Review, feat. XFX & PowerColor: Polaris Returns (Again)». anandtech.com. Consultado el 24 de noviembre de 2018.
- ↑ Kampman, Jeff (5 de enero de 2017). «The curtain comes up on AMD's Vega architecture». TechReport.com. Consultado el 10 de enero de 2017.
- ↑ Shrout, Ryan (5 de enero de 2017). «AMD Vega GPU Architecture Preview: Redesigned Memory Architecture». PC Perspective. Consultado el 10 de enero de 2017.
- ↑ Kampman, Jeff (26 de octubre de 2017). «AMD's Ryzen 7 2700U and Ryzen 5 2500U APUs revealed». Techreport.com. Consultado el 26 de octubre de 2017.
- ↑ Raevenlord (1 de marzo de 2017). «On NVIDIA's Tile-Based Rendering». techPowerUp.
- ↑ «Vega Teaser: Draw Stream Binning Rasterizer». Anandtech.com.
- ↑ «Radeon RX Vega Revealed: AMD promises 4K gaming performance for $499 – Trusted Reviews». Trustedreviews.com. 31 de julio de 2017. Archivado desde el original el 14 de julio de 2017. Consultado el 23 de febrero de 2023.
- ↑ «The curtain comes up on AMD's Vega architecture». Techreport.com. Archivado desde el original el 1 de septiembre de 2017. Consultado el 23 de febrero de 2023.
- ↑ Kampman, Jeff (23 de enero de 2018). «Radeon RX Vega primitive shaders will need API support». Techreport.com. Consultado el 29 de diciembre de 2018.
- ↑ «ROCm-OpenCL-Runtime/libUtils.cpp at master · RadeonOpenCompute/ROCm-OpenCL-Runtime». github.com. 3 de mayo de 2017. Consultado el 10 de noviembre de 2018.
- ↑ «The AMD Radeon RX Vega 64 & RX Vega 56 Review: Vega Burning Bright». Anandtech.com. 14 de agosto de 2017. Consultado el 16 de noviembre de 2017.
- ↑ «AMD's Vega Mobile Lives: Vega Pro 20 & 16 in Updated MacBook Pros In November». Anandtech.com. 30 de octubre de 2018. Consultado el 10 de noviembre de 2018.
- ↑ «AMD Announces Radeon Instinct MI60 & MI50 Accelerators: Powered By 7nm Vega». Anandtech.com. 6 de noviembre de 2018. Consultado el 10 de noviembre de 2018.
- ↑ «AMD Unveils World’s First 7nm Gaming GPU – Delivering Exceptional Performance and Incredible Experiences for Gamers, Creators and Enthusiasts». 1 de septiembre de 2019. Consultado el 22 de febrero de 2023.
- ↑ Ferreira, Bruno (16 de mayo de 2017). «Ryzen Mobile APUs are coming to a laptop near you». Tech Report. Consultado el 16 de mayo de 2017.
- ↑ «AMD Unveils World’s First 7nm Datacenter GPUs -- Powering the Next Era of Artificial Intelligence, Cloud Computing and High Performance Computing (HPC)». 11 de junio de 2018. Consultado el 23 de febrero de 2022.
- ↑ «RadeonFeature». x.Org. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Tahiti GPU Specs». TechPowerUp. Consultado el 20 de noviembre de 2022.
- ↑ «AMD Pitcairn GPU Specs». TechPowerUp. Consultado el 20 de noviembre de 2022.
- ↑ «AMD Cape Verde GPU Specs». TechPowerUp. Consultado el 20 de noviembre de 2022.
- ↑ «AMD Oland GPU Specs». TechPowerUp. Consultado el 20 de noviembre de 2022.
- ↑ «AMD Hainan GPU Specs». TechPowerUp. Consultado el 20 de noviembre de 2022.
- ↑ «AMD Bonaire GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Hawaii GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Topaz GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Tonga GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Fiji GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Ellesmere GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Baffin GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Lexa GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Vega 10 GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Vega 12 GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
- ↑ «AMD Vega 20 GPU Specs». TechPowerUp. Consultado el 21 de noviembre de 2022.
{kind=link}
Enlaces externos
editar Datos: Q20714248
Datos: Q20714248